
Category: Deliverable
1. Improvements in Architecture
Filebeat VS Logstash:
Filebeat and Logstash provide inconsequential transports for centralizing and forwarding log information. It supports maintaining simple objects by providing a very easy way to manage and centralize files, folders and logs. In other words, Logstash is described as collecting, parsing, and augmenting data. The important difference between Logstash and Filebeat is their functionality, Filebeat consumes fewer resources. But in general, Logstash consumes various inputs, and dedicated beats do the job of collecting data with minimal RAM and CPU.
In order to improve the efficiency of the ELK stack, it is best to use the combination of these two tools together. Logstash acts as an aggregator – pulling data from various sources and pushing it into a pipeline, usually into Elasticsearch, but also into a buffer component in large production environments. It’s worth mentioning that the latest version of Logstash also includes support for persistent queues when storing message queues on disk. On the other hand, Filebeat and other members of the Beats family act as lightweight agents deployed on edge hosts, pumping data into Logstash for aggregation, filtering, and enrichment.
2. Improvements on Elasticsearch
What is Elasticsearch?
Elasticsearch is a distributed document store based on the Apache Lucene library specializing in full-text search for schema-free documents and provides access to raw event-level data.
- Cluster:
ElasticSearch can be used as a standalone single search server. However, in order to handle large data sets and achieve fault tolerance and high availability, ES can run on many servers that cooperate with each other. The collection of these servers is called a cluster.
- Node:
Each server that forms a cluster is called a node
- Shard:
When there are a large number of documents, one node may not be enough due to memory limitations, insufficient disk processing power, inability to respond to client requests fast enough, etc. In this case, the data can be divided into smaller slices. Each slice is put on a different server.
When the index of your query is distributed over multiple shards, ES sends the query to each relevant shard and combines the results without the application being aware of the existence of the shards. I.e., the process is transparent to the user.
- Replia:
To increase query throughput or achieve high availability, you can use a sharded replica.
A replica is an exact copy of a slice, and each slice can have zero or more copies. there can be many identical slices in ElasticSearch, one of which is selected to change the index operation, and this particular slice is called the master slice.
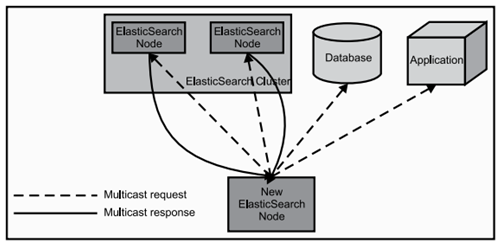
Pre-filter implementation principle:
The data node determines whether there is an intersection between a Range query and sharding, depending on an important feature of Lucene: PointValues.
Pre-filter will not be executed in all query processes. It will be executed only if the following conditions are met at the same time:
- The number of shards to be queried is greater than 128 (specified by pre_filter_shard_size)
- Aggregation requests do not require access to all docs.
In addition, although the numerical query of the non-Date type will also go through the pre-filter process, it will not judge the range internally.
In order to improve on the current ElasticSearch, the pre-filtering phase can be adapted to send only one request per node in this phase, covering all slices on the node. If a cluster has thousands of slices on three data nodes, the number of network requests will change from thousands to three or less during the initial search phase, regardless of the number of slices searched.
Improvement in Network
Each Elasticsearch node has two different network interfaces. Clients use its HTTP interface to send requests to Elasticsearch’s REST APIs, but nodes use the transport interface to communicate with other nodes. The transport interface is also used for communication with remote clusters. We come to acknowledge an abstract application programming interface (API) for the transport layer that enables dynamic selection of transport protocols and network paths at runtime. This API enables faster deployment of new protocols and protocol features without requiring modifications to the application. The specified API follows the transport service architecture and provides asynchronous, atomic messaging. It is intended to replace the BSD socket API as a common interface to the transport layer, in an environment where endpoints can choose from multiple interfaces and potential transport protocols. We want to apply this abstraction layer into the process of ElasticSearch in order to improve its efficiency.
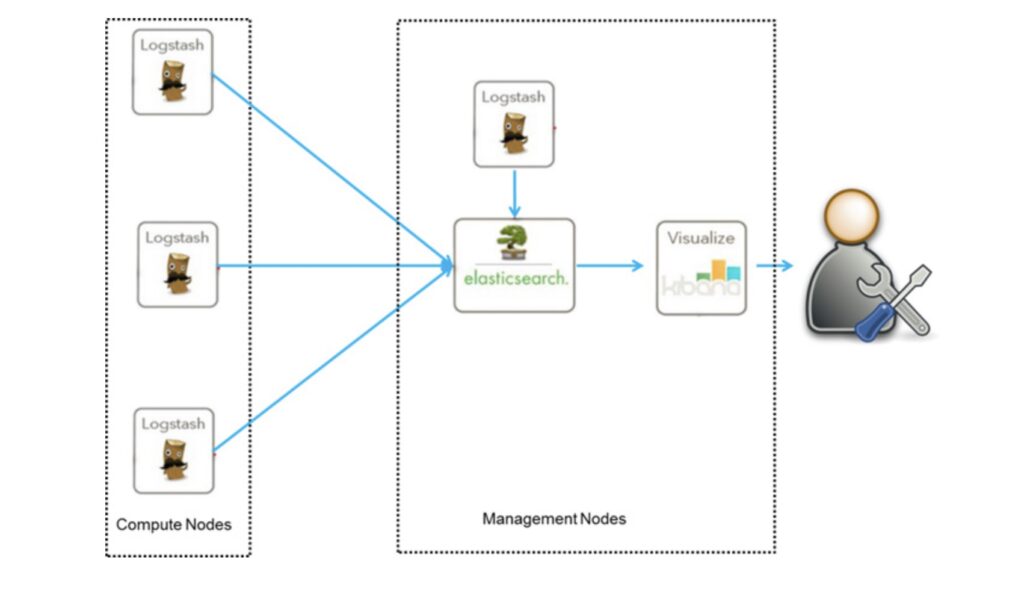
Here is a diagram of the basic framework of the ELK, the convenience of this framework is that it is simple to build and easy to use. On the other side, Logstash takes up a lot of CPU and memory to run and it costs a lot of resources. In addition, there is no message queue cache, and there is a high potential for data loss.
This framework is distributed by Logstash on each node to collect relevant logs and data, and after analysis and filtering, it is sent to Elasticsearch on the remote server for storage. Elasticsearch compresses and stores data in shards and provides multiple APIs for users to query and operate. Users can also easily query logs by configuring Kibana Web, and generating reports based on the data.
The ELK also provides the basic functionality of a log management system. However, in ELK, LogStash often causes deadlocks when loading log files from multiple sources to a central server. Therefore, these three systems do not completely solve all the problems of centralized log management systems.
[1] http://eprints.uet.vnu.edu.vn/eprints/id/eprint/1994/1/paper113-van.nam.pdf
A More Efficient Log Management System
Ruijie Jin, Zixin Yao
Log files are the primary data source for network observability and they contain records of all events including operations within systems, applications, software or server, thus, it is essential to monitor these files in order to protect them from outside attacks. Nevertheless, there are tons of log files generated by the computer every day, and the primary way to secure these files right now is by log management, the practice of continuously gathering, storing and analyzing log files from applications. Log management can help us to identify technical issues when we are unable to locate where the problem is, also strengthen the security because it can determine unusual activities and notify users.
One of the most popular log file management stacks used worldwide is the ELK stack. It stands for open source projects: Elasticsearch, Logstash and Kibana; Elasticsearch is a search and analytics engine. Logstash is a server‑side data processing pipeline that ingests data from multiple sources simultaneously, transforms it, and then sends it to a “stash” like Elasticsearch. And Kibana lets users visualize data with charts and graphs in Elasticsearch. However, there are some major problems with the ELK stack while monitoring logging, first, Logstash is not scalable which creates files collision and leads to file loss. Also, there might be log files loss during the process of Logstash. Last, unlike the existing log management platforms, the ELK stack is not a real-time management system so it cannot detect and notify users of potential attacks.
As mentioned above, even though there exist some crucial problems with the ELK stack, it is still one of the most used open-source software for log management, thus, we proposed some improvements based on the ELK stack. Specifically on the efficiency of log monitoring.